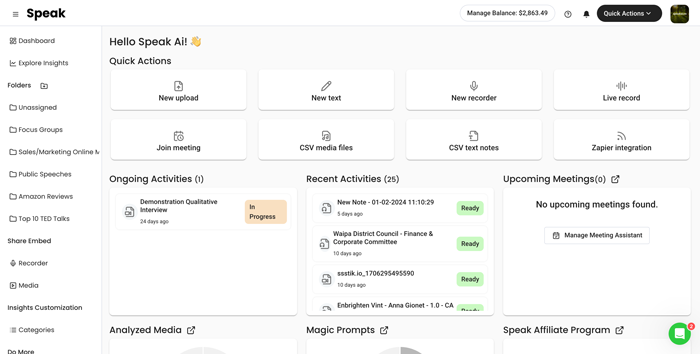
Learn about how to use Speak to improve your workflow and learn about the world of voice technology, transcription and AI analysis along the way.
Start your 7-day fully-featured trial!
Use Speak's powerful AI to transcribe, analyze, automate and produce incredible insights for you and your team.